
Hay un problema que aparece tarde o temprano en cualquier proyecto que usa LLMs en producción: ¿qué modelo elijo para cada petición? Los modelos pequeños son baratos y rápidos, pero se quedan cortos en tareas complejas. Los frontiers dan resultados excelentes, pero llamarlos para clasificar un ticket de soporte es como usar un bisturí de cirujano para abrir un sobre. Y si mezclas ambos, acabas con un sistema de routing propio que tienes que mantener, versionar y ajustar cada vez que aparece un modelo nuevo.
Model Router es la respuesta de Microsoft a ese problema. Un deployment único en Azure AI Foundry que, en tiempo real, analiza cada prompt y lo dirige al modelo más adecuado del pool sin que tu aplicación tenga que saber nada sobre qué modelo está respondiendo. Vamos a ver cómo funciona, qué modelos incluye en su versión más reciente (2025-11-18), cómo se despliega y cuándo tiene sentido usarlo.
Qué es Model Router y cómo toma sus decisiones
Model Router no es un servicio de reglas estáticas ni un wrapper que alterna modelos por round-robin. Es un modelo ML ligero, entrenado específicamente para hacer routing. Analiza el prompt completo incluyendo el system message, el historial de conversación, las definiciones de herramientas (tools) y los mensajes de usuario y estima qué modelo del pool va a dar el mejor resultado para esa petición concreta. Todo esto añade una latencia despreciable comparada con la inferencia del modelo destino.
El proceso tiene tres pasos. Primero, el router entiende el prompt: identifica qué pide, qué dificultad tiene y qué tipo de razonamiento requiere. Segundo, selecciona el modelo más adecuado del pool, aplicando el modo de enrutamiento que hayas configurado. Tercero, delega la petición y devuelve la respuesta con el campo «model» en el JSON indicando exactamente qué modelo la procesó. Esa transparencia es importante: tienes visibilidad completa de a dónde va cada token.
Una cosa que vale la pena mencionar: el router no almacena tus prompts. Hace el análisis en memoria, respeta los límites de zona de datos de tu deployment y no cruza fronteras geográficas. Eso es relevante si operas bajo marcos de cumplimiento europeos.
Los tres modos de enrutamiento
Puedes influir en la lógica de selección con tres modos. Balanced es el predeterminado y el más adecuado para la mayoría de los escenarios: busca el modelo más económico dentro de una banda de calidad del 1-2% respecto al mejor modelo disponible para esa petición. Es decir, sacrifica muy poca calidad a cambio de un ahorro de coste real.
Quality ignora el coste y siempre elige el modelo con mayor puntuación de calidad para el prompt. Tiene sentido en flujos críticos: análisis legal, resúmenes médicos, razonamiento complejo en un agente. Cost amplía la banda de calidad aceptable hasta el 5-6% para maximizar el ahorro útil en pipelines de clasificación masiva o generación de texto simple a alto volumen.
Figura 2. Selector del modo de enrutamiento (Balanced / Quality / Cost) en la configuración personalizada (fuente: learn.microsoft.com).
Nota: Los cambios en el modo de enrutamiento pueden tardar hasta cinco minutos en propagarse. Planifícalo si cambias la configuración en entornos de producción.
18 modelos, cuatro proveedores: el pool de la versión 2025-11-18
La versión más reciente de Model Router la 2025-11-18 es un salto importante respecto a las anteriores. Pasa de los cuatro modelos OpenAI de la versión 2025-05-19 a un pool de 18 modelos de cuatro proveedores distintos. Eso cambia bastante la naturaleza del producto: ya no es solo routing entre GPTs, sino una capa de abstracción multi-vendor real.
Los modelos OpenAI siguen siendo el núcleo: gpt-4.0, gpt-4.0-mini, gpt-4.1, gpt-4.1-mini, gpt-4.1-nano, o4-mini, gpt-5-nano, gpt-5-mini, gpt-5, gpt-5-chat, gpt-5.2 y gpt-5.2-chat. A esto se suman, en preview, DeepSeek-V3.1 y DeepSeek-V3.2, Llama-4-Maverick-17B-128E-Instruct-FP8 de Meta, grok-4 y grok-4-fast-reasoning de xAI, y los modelos de Anthropic: claude-haiku-4-5, claude-sonnet-4-5, claude-opus-4-1 y claude-opus-4-6.
Nota: Los modelos Claude de Anthropic requieren un paso adicional: hay que desplegarlos manualmente desde el catálogo de modelos del portal Foundry antes de incluirlos en el pool del router. El resto de modelos no necesitan deployment previo — el router los invoca directamente.
Ojo con el contexto: la ventana de contexto efectiva del router está limitada por el modelo más pequeño del pool. Si necesitas ventanas grandes de forma consistente, usa la función de model subset para excluir los modelos con ventanas menores.
Facturación: pagas por el modelo que realmente usas
El modelo de pricing es directo. La facturación se aplica al modelo subyacente que el router selecciona para cada petición no hay coste adicional por el router en sí mismo. Si el router decide que un prompt sencillo lo puede manejar gpt-4.1-nano, se te factura al precio de gpt-4.1-nano. Si selecciona gpt-5 para una tarea compleja, pagas el precio de gpt-5.
Esto tiene una implicación práctica importante para los arquitectos: el ahorro de coste no es garantizado ni fijo depende de la distribución real de tu tráfico. En modo Balanced, la mayoría de las peticiones cotidianas acabarán en modelos de gama media, pero las tareas complejas escalarán a los frontiers. Para cuantificar el ahorro antes de comprometerte, hay un repositorio de análisis de distribución en GitHub (ModelRouter-Distribution, de @guygregory) que te permite ejecutar tu corpus de prompts y ver exactamente a qué modelo iría cada uno.
El monitoring de costes se hace desde Azure Portal: en Cost analysis, filtra por el tag Deployment con el nombre de tu deployment del router. Así ves el coste agregado del endpoint sin tener que cruzar datos de múltiples recursos.
Cómo desplegar Model Router
El despliegue sigue exactamente el mismo proceso que cualquier otro modelo en Foundry. Lo que cambia es que tienes dos opciones: Default y Custom. La primera te lo configura todo en modo Balanced con el pool completo de modelos. Es suficiente para empezar y para la mayoría de los casos de uso generales.
Figura 1. Pantalla de despliegue de model-router en el portal de Microsoft Foundry (fuente: learn.microsoft.com).
Despliegue por defecto desde el portal
Desde el portal de Microsoft Foundry, ve al catálogo de modelos y busca model-router. Selecciónalo y elige Default settings. Con eso tienes un deployment en modo Balanced enrutando al pool completo en cuestión de minutos. No hay configuración adicional que hacer.
Despliegue programático con la API REST
Si prefieres automatizar el despliegue con la Management API — por ejemplo desde un pipeline de CI/CD o una plantilla Bicep — el cuerpo de la petición PUT es el siguiente. Primero consigue el token de gestión:
export AZURE_AI_AUTH_TOKEN=$(
az account get-access-token \
–resource https://management.azure.com \
–query accessToken -o tsv
)
Y luego el deployment con configuración por defecto:
curl -X PUT \
«https://management.azure.com/subscriptions/<SUB_ID>/resourceGroups/<RG>/\
providers/Microsoft.CognitiveServices/accounts/<ACCOUNT>/deployments/model-router-deployment\
?api-version=2025-10-01-preview» \
-H «Content-Type: application/json» \
-H «Authorization: Bearer $AZURE_AI_AUTH_TOKEN» \
-d ‘{
«sku»: {«name»: «GlobalStandard», «capacity»: 10},
«properties»: {
«model»: {
«format»: «OpenAI»,
«name»: «model-router»,
«version»: «2025-11-18»
}
}
}’
Despliegue personalizado: routing mode y model subset
Si eliges Custom settings, puedes seleccionar el modo de enrutamiento y restringir el pool a un subconjunto de modelos aprobados. El model subset es también tu mecanismo de gobierno: los modelos nuevos que aparezcan en versiones futuras del router no se añaden automáticamente a tu subset hay que incorporarlos explícitamente. Eso da control de cumplimiento sin necesidad de gestión continua.
Figura 3. Selección de subconjunto de modelos para restringir el enrutamiento a modelos aprobados (fuente: learn.microsoft.com).
Un ejemplo con modo Balanced, subset restringido a tres modelos, vía REST API:
curl -X PUT \
«https://management.azure.com/…/deployments/model-router-deployment\
?api-version=2025-10-01-preview» \
-H «Content-Type: application/json» \
-H «Authorization: Bearer $AZURE_AI_AUTH_TOKEN» \
-d ‘{
«sku»: {«name»: «GlobalStandard», «capacity»: 10},
«properties»: {
«model»: {
«format»: «OpenAI»,
«name»: «model-router»,
«version»: «2025-11-18»
},
«routing»: {
«mode»: «balanced»,
«models»: [
{«format»: «OpenAI», «name»: «gpt-4.1», «version»: «2025-04-14»},
{«format»: «OpenAI», «name»: «gpt-5.2-chat», «version»: «2025-12-11»},
{«format»: «Meta», «name»: «Llama-4-Maverick-17B-128E-Instruct-FP8», «version»: «1»}
]
}
}
}’
Nota: Selecciona siempre al menos dos modelos en el subset. Con un único modelo pierdes el routing, el ahorro de costes y el failover automático — básicamente conviertes el router en un passthrough caro.
Consumir Model Router desde tu aplicación
Aquí está una de las partes más cómodas del producto: la API es idéntica a la de cualquier deployment de Azure OpenAI. Si ya tienes código que llama a Chat Completions, el único cambio es apuntar el parámetro model al nombre de tu deployment del router. No hay SDK nuevo que aprender.
Python con el SDK de OpenAI (Chat Completions)
from openai import AzureOpenAI
client = AzureOpenAI(
azure_endpoint=»https://<tu-recurso>.openai.azure.com/»,
api_key=»<tu-api-key>»,
api_version=»2024-10-21″,
)
response = client.chat.completions.create(
model=»model-router-deployment», # nombre del deployment del router
messages=[
{«role»: «system», «content»: «Eres un asistente técnico de soporte.»},
{«role»: «user», «content»: «Explica la diferencia entre TCP y UDP.»},
],
)
print(response.choices[0].message.content)
print(f»Modelo usado: {response.model}») # aqui ves qué modelo respondio
Fíjate en la última línea: response.model te devuelve el modelo subyacente que procesó la petición. Logea ese campo. Es tu principal señal de observabilidad para entender cómo se distribuye el tráfico y calcular el coste real por tipo de petición.
Integración con Foundry Agent Service
Desde la versión 2025-11-18, Model Router es compatible con el servicio de agentes de Foundry, incluyendo escenarios con herramientas (tool calling). Puedes configurarlo como modelo base de un agente desde el Agent Playground: simplemente selecciónalo en el dropdown de modelo al crear o editar el agente.
El router seleccionará dinámicamente el modelo más adecuado para cada paso del agente: un modelo pequeño para una clasificación inicial, un modelo de razonamiento para el análisis complejo, y así sucesivamente. Ojo: cuando uses herramientas del servicio de agentes, el router enruta exclusivamente a modelos OpenAI. Los modelos de terceros (Claude, DeepSeek, Llama, Grok) no participan en esos flujos por ahora.
Ver la distribución de tráfico entre modelos
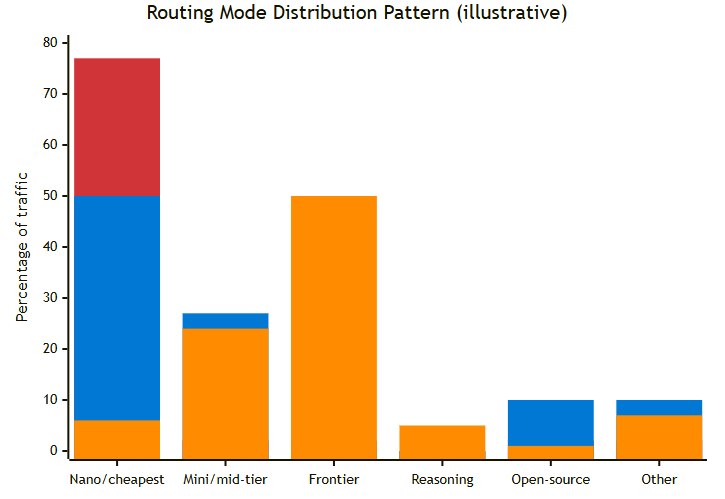
Figura 4. Distribución del tráfico por modo de enrutamiento: Cost (rojo) concentra el tráfico en modelos pequeños; Quality (naranja) lo dirige a modelos frontier (fuente: learn.microsoft.com / ModelRouter-Distribution).
El gráfico de distribución muestra claramente el impacto de cada modo. En Cost mode, la mayor parte del tráfico se concentra en los modelos nano y mini. En Balanced se reparte de forma más uniforme según la dificultad de cada prompt. En Quality mode el router dirige sistemáticamente hacia los modelos frontier.
Para monitorizar en producción, ve a la página de Monitoring > Metrics de tu recurso en Azure Portal, filtra por el nombre del deployment del router y divide la vista por underlying model. Eso te da una tabla en tiempo real de a dónde van tus tokens y por extensión, tu presupuesto.
Disponibilidad regional y límites de tasa
Model Router está disponible, a fecha de mayo de 2026, en East US 2 y Sweden Central, con soporte para deployments de tipo Global Standard y Data Zone Standard. La segunda opción es relevante para organizaciones con requisitos de residencia de datos en la UE: Sweden Central con Data Zone Standard mantiene el procesamiento dentro de los límites europeos.
Los límites de tasa por defecto son 250 RPM y 250.000 TPM en Global Standard, y 150 RPM y 150.000 TPM en Data Zone Standard. Las cuentas Enterprise y MCA-E tienen límites más altos (400/300 RPM respectivamente). Si necesitas más capacidad, el camino habitual es solicitar aumento de cuota desde el portal de Azure.
Cuándo tiene más sentido un deployment directo
Model Router no es la solución para todo. Hay escenarios donde un deployment directo a un modelo específico sigue siendo la elección correcta.
El caso más claro es cuando necesitas el mismo modelo en cada petición sin excepción por reproducibilidad, por auditoría o porque el contrato con el cliente lo exige. El router es transparente (te dice qué modelo usó), pero no garantiza determinismo: dos prompts idénticos pueden acabar en modelos distintos. Si eso es un problema para tu caso de uso, ve con un deployment fijo.
También tiene sentido un deployment directo si tu tráfico es completamente homogéneo por ejemplo, siempre procesás documentos legales de alta complejidad. Ahí el router siempre va a seleccionar el mismo modelo frontier y no hay ahorro que capturar. Pagar el overhead de routing sin beneficio no tiene sentido.
El patrón que mejor funciona en la práctica es el híbrido: Model Router para el tráfico general de la aplicación y deployments directos para flujos especializados donde el control del modelo es crítico. Los dos coexisten perfectamente en el mismo recurso Foundry.
Conclusión: empieza en Balanced, deja que los datos hablen
Model Router resuelve un problema real de forma elegante. La mayor parte de los equipos que están gestionando aplicaciones con LLMs en producción tienen una mezcla de tareas simples y complejas, y están pagando el precio del modelo más caro para todas ellas por simplicidad operativa. El router quita ese coste sin añadir complejidad al código.
La recomendación de la documentación oficial es la que tiene más sentido: empieza con Balanced mode y deja correr tráfico real durante unas semanas. Observa la distribución desde Azure Monitor, entiende qué tipos de peticiones van a cada modelo y entonces toma decisiones informadas sobre si vale la pena mover algunos flujos a Cost mode o reservar Quality mode para los caminos críticos.
Ojo con el model subset como herramienta de gobierno: es la forma más limpia de controlar qué modelos pueden procesar datos de tu organización. Úsalo desde el primer día si trabajas con información sensible o si tu equipo de seguridad necesita aprobar explícitamente cada proveedor de modelos.
Y si ya tienes aplicaciones corriendo contra Azure OpenAI el cambio es literalmente cambiar el nombre del deployment en el parámetro model. No hay razón para no probarlo.
Fuentes y documentación oficial
- Conceptos de Model Router: https://learn.microsoft.com/en-us/azure/foundry/openai/concepts/model-router
- Cómo funciona el router internamente: https://learn.microsoft.com/en-us/azure/foundry/openai/concepts/model-router-how-it-works
- Guía de despliegue y uso: https://learn.microsoft.com/en-us/azure/foundry/openai/how-to/model-router
- Novedades en Model Router: https://learn.microsoft.com/en-us/azure/foundry/foundry-models/whats-new-model-router
- Arquitectura de cargas LLM cost-aware: https://techcommunity.microsoft.com/blog/azure-ai-foundry-blog/architecting-cost-aware-llm-workloads-with-model-router-in-microsoft-foundry/4514440
- Muestras y demos en GitHub: https://github.com/microsoft-foundry/foundry-samples/tree/main/samples/python/foundry-models/model-router
- Análisis de distribución de modelos: https://github.com/guygregory/ModelRouter-Distribution