
Microsoft ha anunciado la disponibilidad general (GA) de Foundry Local, la solución para ejecutar modelos de IA directamente en dispositivos Windows, macOS y Linux sin depender de la nube ni pagar por tokens. Esto es lo que necesitas saber para empezar hoy mismo.
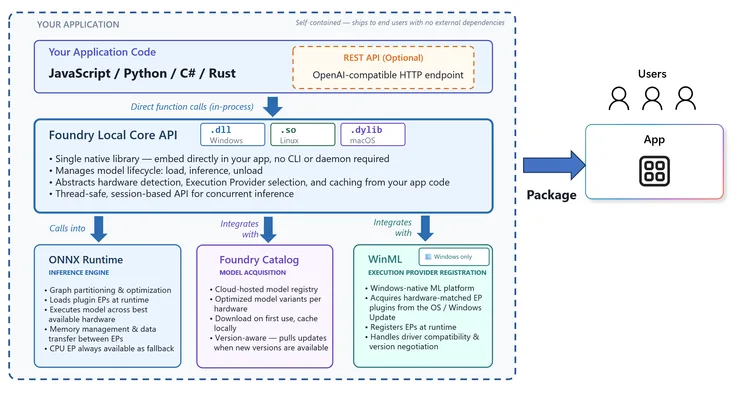
Figura: Arquitectura de Foundry Local (fuente: devblogs.microsoft.com/foundry)
Qué es Foundry Local y por qué importa este GA
Foundry Local existe para resolver un problema concreto: hay escenarios donde la inferencia en la nube no es viable. Puede ser por latencia, por restricciones de privacidad, por costes en volumen, o simplemente porque la aplicación necesita funcionar sin conexión. Hasta ahora, montar un pipeline de inferencia local requería bastante trabajo gestionar runtimes, adaptar el hardware disponible, manejar descargas de modelos. Foundry Local lo hace transparente.
El anuncio de GA publicado el pasado mes de abril en el blog oficial de Microsoft Foundry deja claro que esto no es el final del camino, sino el inicio de una plataforma estable sobre la que construir. En palabras del propio equipo: «un hito, no una línea de meta». Con la GA llega soporte oficial, SLA de calidad y un compromiso de backwards compatibility para los SDKs disponibles.
La propuesta es directa: una API compatible con el formato OpenAI la misma que ya usas si trabajas con Azure OpenAI Service pero apuntando a un endpoint local en tu máquina. Cambiar entre inferencia local y en la nube es cuestión de modificar la URL base y la clave. Nada más.
Hardware soportado: CPU, GPU y NPU sin código extra
Una de las partes más cuidadas de Foundry Local es el manejo del hardware. El SDK detecta automáticamente qué capacidades tiene el dispositivo y descarga la variante del modelo optimizada para ese contexto. No necesitas escribir código de detección ni condicionales según la GPU disponible. Simplemente funciona.
En Windows, la integración va un paso más allá gracias a Windows ML (WinML). El paquete específico para Windows foundry-local-sdk-winml se comunica directamente con el runtime de WinML y aprovecha GPUs y NPUs a través de los plugins de ejecución del sistema operativo. Esto significa que si tienes una Copilot+ PC con NPU integrada, Foundry Local la usará sin que tengas que hacer absolutamente nada adicional.
En macOS, el soporte es nativo para Apple Silicon vía Metal. En Linux x64, la ejecución cae sobre CPU con posibilidad de GPU si el entorno lo permite. Y si el dispositivo no tiene aceleración hardware disponible, el fallback a CPU es automático. Sin errores, sin configuración adicional.
Modelos disponibles en el catálogo
Foundry Local trae un catálogo curado de modelos optimizados para inferencia en dispositivo. No es un listado de cientos de variantes sin criterio — son modelos seleccionados por su rendimiento en hardware de consumo. Entre ellos encontramos:
- Familia Phi los modelos pequeños de Microsoft, especialmente buenos en razonamiento
- Qwen 2.5 (0.5B, entre otros) muy ligero, arranque rápido
- Mistral buen equilibrio calidad/tamaño
- Deepseek modelos de código con buena reputación en la comunidad
- Whisper para transcripción de audio en local
- GPT OSS variantes open source compatibles con el formato OpenAI
La descarga es reanudable si se corta la conexión a mitad, retoma desde donde estaba. Y una vez descargado, el modelo queda en caché local: las siguientes ejecuciones no necesitan red.
Primeros pasos en Windows con Node.js
Prerrequisitos
Para seguir este ejemplo necesitas Node.js 20 o superior instalado en tu máquina Windows. Nada más. No hace falta tener Azure, ni cuenta de Microsoft, ni subscription activa.
Instalación del SDK
En Windows usamos el paquete específico que integra con Windows ML para máximo rendimiento:
npm install foundry-local-sdk-winml openai
Si vas a desarrollar una aplicación multiplataforma (Windows + macOS + Linux), el paquete base sin WinML también funciona en Windows, aunque sin la aceleración nativa del sistema:
npm install foundry-local-sdk openai
Tu primera aplicación: chat local con streaming
El siguiente código descarga el modelo Qwen 2.5 de 0.5B parámetros, lo carga en memoria, lanza dos completions (una directa y otra en streaming) y finalmente descarga el modelo. Todo en local, sin llamadas a la nube. Guárdalo en un fichero app.js y ejecútalo con node app.js.
import { FoundryLocalManager } from ‘foundry-local-sdk’;
// Inicializa el SDK de Foundry Local
const manager = FoundryLocalManager.create({
appName: ‘foundry_local_samples’,
logLevel: ‘info’
});
// Descarga y registra los execution providers disponibles
const eps = manager.discoverEps();
if (eps.length > 0) {
let currentEp = »;
await manager.downloadAndRegisterEps((epName, percent) => {
if (epName !== currentEp) {
if (currentEp !== ») process.stdout.write(‘\n’);
currentEp = epName;
}
process.stdout.write(`\r ${epName.padEnd(30)} ${percent.toFixed(1).padStart(5)}%`);
});
process.stdout.write(‘\n’);
}
// Obtiene el modelo del catálogo y lo descarga (si no está en caché)
const modelAlias = ‘qwen2.5-0.5b’;
const model = await manager.catalog.getModel(modelAlias);
await model.download((progress) => {
process.stdout.write(`\rDescargando… ${progress.toFixed(2)}%`);
});
// Carga el modelo en memoria
await model.load();
// Crea el cliente de chat
const chatClient = model.createChatClient();
// Completion directa (no streaming)
const completion = await chatClient.completeChat([
{ role: ‘user’, content: ‘Why is the sky blue?’ }
]);
console.log(completion.choices[0]?.message?.content);
// Completion en streaming token a token
for await (const chunk of chatClient.completeStreamingChat([
{ role: ‘user’, content: ‘Write a short poem about programming.’ }
])) {
const content = chunk.choices?.[0]?.delta?.content;
if (content) process.stdout.write(content);
}
console.log(‘\n’);
// Descarga el modelo de memoria
await model.unload();
El código completo de este ejemplo, junto con las variantes para Python, C# y Rust, está disponible en el repositorio oficial de Foundry Local en GitHub:
git clone https://github.com/microsoft/Foundry-Local.git
cd Foundry-Local/samples/js/native-chat-completions
Compatibilidad con la API de OpenAI
Foundry Local expone un endpoint HTTP local compatible con el formato de OpenAI. Esto tiene una implicación práctica inmediata: cualquier código que ya uses con Azure OpenAI Service o con la API de OpenAI puede reutilizarse apuntando al endpoint local con el paquete openai de npm, con el SDK oficial de OpenAI en Python, con Semantic Kernel, con LangChain. Lo que ya funciona en la nube, funciona en local sin reescritura.
Ojo con un detalle: el endpoint HTTP local es opcional. El SDK nativo tiene su propia API (FoundryLocalManager, model.createChatClient(), etc.) que es más eficiente y no requiere levantar un servidor. Pero si tu arquitectura ya está montada sobre llamadas HTTP a la API de OpenAI, puedes usar el modo compatible y migrar de forma gradual.
Casos de uso donde Foundry Local encaja bien
La documentación oficial menciona cuatro escenarios representativos, y todos tienen algo en común: la privacidad o la disponibilidad offline no son negociables.
- Asistentes de escritorio: donde el usuario no quiere que sus datos salgan del dispositivo
- Herramientas médicas de apoyo a la decisión: que deben funcionar en entornos sin conexión o con restricciones regulatorias sobre el dato
- Compañeros de programación privados: para equipos que trabajan en código propietario y no pueden enviarlo a servicios externos
- Aplicaciones con modo offline: donde la IA debe seguir respondiendo aunque no haya red
A esto yo añadiría un quinto escenario que me parece relevante para partners y arquitectos: prototipado rápido. Foundry Local permite iterar con modelos localmente sin preocuparse por costes de inferencia durante la fase de desarrollo, y luego migrar a Azure AI Foundry para producción cambiando literalmente la URL del endpoint.
Un paso práctico para empezar
La GA de Foundry Local es una apuesta clara de Microsoft por la IA on-device como complemento no sustituto de la inferencia en la nube. El catálogo curado, la detección automática de hardware y la compatibilidad con la API de OpenAI hacen que la barrera de entrada sea baja para cualquier equipo que ya trabaje en el ecosistema Azure AI.
Si quieres tenerlo funcionando hoy mismo: instala Node.js 20, lanza npm install foundry-local-sdk-winml openai, copia el código de ejemplo y ejecuta node app.js. En cuestión de minutos más el tiempo de descarga del modelo tendrás un chat completamente local corriendo en tu máquina. Sin Azure, sin clave de API, sin coste por token.
El repositorio de ejemplos en GitHub (github.com/microsoft/Foundry-Local) incluye variantes para Python, C# y Rust, además de escenarios más avanzados. Vale la pena echarle un vistazo antes de construir algo desde cero.
Fuentes
Anuncio oficial GA: https://devblogs.microsoft.com/foundry/foundry-local-ga/
Guia de inicio (Windows / JavaScript): https://learn.microsoft.com/en-us/azure/foundry-local/get-started?tabs=windows&pivots=programming-language-javascript
Repositorio de ejemplos: https://github.com/microsoft/Foundry-Local